Flink电商项目实践 用户行为分析与热门商品TopN统计全流程解析
在电商领域,实时分析用户行为并快速识别热门商品是提升业务决策效率的关键。本项目基于Apache Flink,构建一个从数据采集到热门商品统计(TopN)的完整实时分析流程。我们将重点解析电商用户行为分析的核心步骤,并深入实现一个基于滑动窗口的热门商品TopN统计模块。
第一部分:电商用户行为分析整体架构与步骤解析
一个典型的Flink电商用户行为分析项目通常遵循以下步骤:
- 数据源模拟与接入:我们需要模拟或接入真实的用户行为日志数据流。数据通常包含用户ID、商品ID、行为类型(点击、购买、收藏等)、时间戳等关键字段。可以使用Flink的
DataStreamSource从Kafka、文件或自定义的Source函数中读取数据。
- 数据清洗与格式化:原始数据流可能包含不完整或格式错误的记录。通过Flink的
Filter和Map算子,我们可以过滤掉无效数据,并将原始字符串转换为结构化的Java Bean或Tuple,便于后续处理。
- 用户行为定义与分流:根据业务需求,定义核心用户行为事件(如页面浏览、商品点击、加入购物车、下单、支付等)。使用
Split和Select算子,或更灵活的Side Output(侧输出流)将数据流按行为类型进行分流,为不同的分析任务提供独立的数据流。
- 关键业务指标实时计算:这是分析的核心。常见的实时指标包括:
- 实时PV/UV统计:使用滚动窗口(Tumbling Window)统计网站或特定页面的页面浏览量(PV)和独立访客数(UV)。UV统计通常借助Bloom Filter或Flink的
HyperLogLog进行近似去重,以节省状态存储空间。
- 用户会话分析:通过
CEP(复杂事件处理)或KeyedProcessFunction,基于用户活动间隙划分会话(Session),分析会话内的行为路径和时长。
- 转化率分析:追踪用户从浏览到下单支付的完整路径,计算各步骤间的转化率,是衡量营销效果和用户体验的重要指标。
第二部分:热门商品统计TopN的实现详解
“热门商品统计”是电商场景下的经典需求,旨在实时找出在过去一段时间内(如最近1小时)被点击或购买次数最多的前N名商品。
实现思路与步骤:
- 数据准备与分组:从用户行为流中过滤出“点击”或“购买”行为。然后,以
商品ID作为Key进行分区(keyBy(itemId))。这样,相同商品的行为事件会被发送到同一个并行子任务中处理。
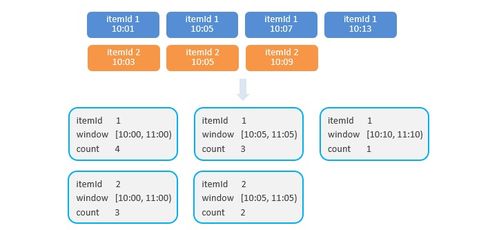
- 开窗与聚合:定义一个滑动窗口(Sliding Window),例如窗口大小1小时,滑动步长5分钟。这样,每5分钟就会输出一次最近1小时的数据统计结果,实现了近乎实时的热点更新。在窗口内,使用
aggregate函数或process函数,对每个商品的行为次数进行累加聚合,输出每个商品在窗口内的总计数。
- 收集全窗口数据并排序:上一步的聚合输出是一个包含了所有商品及其计数的流。为了进行全局排序(而非每个子任务内部排序),我们需要将所有数据在最后5分钟(一个窗口周期)内收集起来。这可以通过在开窗后再次使用
windowAll(一个全局窗口),并配合ProcessAllWindowFunction来实现。
- TopN排序与输出:在
ProcessAllWindowFunction中,我们可以访问到当前窗口中的所有(itemId, count)对。在此处,我们可以使用一个优先级队列(如TreeMap或自定义排序结构)对这些数据进行排序,选出计数最大的前N个商品,并封装成结果输出。
核心代码片段示意(Scala/Java风格):`scala
// 1. 获取点击行为流并分组
val itemClickStream = dataStream.filter(.behavior == "click").keyBy(.itemId)
// 2. 定义滑动窗口并聚合
val windowedStream = itemClickStream
.window(SlidingEventTimeWindows.of(Time.hours(1), Time.minutes(5))) // 1小时窗,5分钟滑
.aggregate(new CountAgg(), new WindowResultFunction()) // 聚合得到(itemId, count, windowEnd)
// 3. 按窗口结束时间分组,收集同一窗口的所有数据
val topNStream = windowedStream
.keyBy(_.windowEnd) // 以窗口结束时间作为Key
.process(new TopNHotItems(5)) // 处理函数,实现TopN排序
// 4. 输出结果
topNStream.print();`
其中,CountAgg是增量聚合函数,WindowResultFunction包装窗口信息,TopNHotItems是关键的KeyedProcessFunction,内部维护一个ListState来存储到达的所有商品计数,并在定时器触发时进行排序输出TopN。
第三部分:项目延伸与“食品加工通用设备”行业应用启示
本项目虽然以通用电商为例,但其架构和Flink技术栈具有高度的通用性。例如,将场景切换到“食品加工通用设备”的B2B电商或物联网平台:
- 数据源变化:用户行为数据可能变为设备采购商的浏览、询盘、对比参数等日志;同时可以接入设备本身的运行状态数据流(如温度、转速、产量)。
- 分析维度拓展:
- 热门设备型号统计:完全复用上述TopN逻辑,统计被询价或关注最多的设备型号,指导库存和营销。
- 设备效能分析:分析不同型号设备在客户实际生产中的运行效率、故障率(结合告警日志流),形成设备效能排行榜,为采购商提供决策依据,也为制造商提供产品改进方向。
- 供应链预警:对关键零部件的采购行为流进行监控,结合时间序列分析,预测未来需求峰值,实现供应链的弹性响应。
****:通过本“第一天”的项目实践,我们掌握了使用Flink构建实时电商用户行为分析管道的基础方法,并重点攻克了实时TopN统计这一核心技术点。这套以事件时间、窗口、状态、定时器为核心的流处理模式,是应对多种实时分析场景的通用“设备”,只需根据不同的“加工原料”(数据)和“工艺要求”(业务逻辑)进行调整,即可在电商、物联网、金融等多个领域发挥巨大价值。
如若转载,请注明出处:http://www.zkgrjsb.com/product/79.html
更新时间:2026-06-19 11:03:34